반응형
Chapter 02. 기초통계_심화과정
분산분석(ANOVA) 완전 정리
1. 주요 개념 요약
분산분석(analysis of variance)
- 셋 이상 집단의 평균 차이를 검정하는 방법
- t-test는 두 집단만 비교 가능, ANOVA는 3개 이상 비교 가능
왜 t-test 여러 번 하면 안 되는가?
- 3집단이면 A–B, A–C, B–C 총 3번의 t-test 필요
- 유의수준 0.05 기준, 오류 누적 확률이 증가함

2. 분산분석의 핵심 구성요소
✔ 실험설계 개념
- 실험에서 결과에 영향을 줄 수 있는 요소: 요인(Factor)
- 요인의 각 조건: 수준(level)
- 실험 단위(관측값): 처리(treatment)
✔ 분산분석의 가정
- 각 집단의 평균이 동일하다는 귀무가설
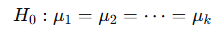
- 실험은 반드시 반복 측정, 랜덤 샘플링
- 독립성 유지 위해 다른 요인(혼재 요인) 통제 필요
3. One-way ANOVA(일원분산분석)
✔ 정의
- 하나의 독립변수(요인)
- 여러 수준 간의 평균 차이를 검정
✔ 예시
- 편의점 A/B/C의 만족도 평균 차이가 있는가?
- 품목별 생산라인 A/B/C에서 생산된 제품 품질 차이가 있는가?

✔ 데이터 구조 형태
- 집단별 관측값 표 형태 (Y₁₁, Y₁₂, … / Y₂₁…)

✔ 분산분석표 구성
- 요인(처리) SS_T, df = k–1
- 오차 SS_E, df = N–k
- 전체 SS_Total, df = N–1

✔ 검정통계량
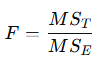
- F가 크면 집단 평균이 다르다는 증거
- F > F 임계값 → 귀무가설 기각
✔ 실제 예제(iris 데이터)
- Species 별 Sepal.Length 평균 차이 검정
- 결과: p-value < 0.05 → 평균 차이가 있음
✔ 사후검정(Post-hoc test)
- Duncan, Bonferroni, Tukey, Scheffé 등
* 이 글은 제로베이스 데이터사이언스 파트타임 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
💡 생각 정리
분산분석은 단순히 평균의 차이가 있는지 아닌지를 넘어, 여러 집단을 한 번에 비교하면서 오류를 통제할 수 있다는 점이 핵심이라는 걸 다시 느꼈다.
특히 여러 요인이 있는 경우 단순 비교로는 원인을 파악하기 어려운데, 분산분석은 요인별 영향을 체계적으로 분리해서 볼 수 있어서 현업에서도 자주 쓰일 수밖에 없다.
또한 사후검정이 꼭 필요하다는 점도 중요한 포인트였다. 단순히 “차이가 있다”에서 끝나는 것이 아니라, 어떤 집단이 어떻게 다른지까지 해석해야 실제 분석 가치가 생긴다는 걸 확실히 이해하게 되었다.
🚀 적용점
마케팅/운영 분석
- 지점별 만족도 차이
- 기획안 A/B/C의 성과 비교
제품·UX 테스트
- 버튼 디자인 3가지 실험 후 클릭률 차이 검정
비즈니스 데이터 분석
- 직군별 업무효율 차이
- 캠페인 유형별 전환율 평균 차이 검정
머신러닝 Feature 분석 전 탐색
- 카테고리형 변수와 타깃 값 평균 관계 확인
사후검정 활용
- 특정 집단끼리만 차이가 큰지 세부적으로 파악
반응형
'데이터' 카테고리의 다른 글
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-19 (0) | 2025.11.26 |
|---|---|
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-18 (0) | 2025.11.25 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-16 (0) | 2025.11.23 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-15 (0) | 2025.11.22 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-14 (0) | 2025.11.21 |