Chapter 01. 기초통계_기초과정
연속형 확률분포 (Continuous Probability Distributions)
주요 개념
연속형 확률변수란 셀 수 없는 실수 범위의 값을 가질 수 있는 변수를 말한다.
예를 들어 사람의 키, 체중, 시간, 거리, 온도 등은 연속형 데이터다.
이때 확률은 단일 값이 아닌 구간으로 계산되며,
이를 위해 확률밀도함수(Probability Density Function, PDF)를 사용한다.
1. 확률밀도함수 (PDF, Probability Density Function)
연속형 확률변수 X의 확률분포는 확률밀도함수 f(x)로 정의된다.
f(x)는 아래 조건을 만족해야 한다.
1. 모든 X에 대해 f(x) ≥ 0
2. 전체 구간의 확률합은 1
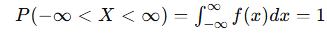
3. 구간 [a, b]의 확률은

즉, 곡선 아래 면적이 확률을 의미한다.
확률밀도함수의 성질
- 단일 값의 확률은 0
P(X = a) = 0 - 구간 확률은 구간의 면적과 동일
P(a < X < b) = P(a ≤ X ≤ b)
기대값(평균)과 분산

즉, 이산형의 “Σ(합)”이 연속형에서는 “∫(적분)”으로 바뀐 형태이다.
🔹 2. 누적분포함수 (CDF, Cumulative Density Function)
확률밀도함수를 적분하면 누적분포함수 F(x)를 얻는다.

- 미분 관계:

누적분포함수의 성질
1. 0 ≤ F(x) ≤ 1
2. b ≥ a → F(b) ≥ F(a)
3. F(b) - F(a) = P(a ≤ X ≤ b)
즉, CDF는 확률이 누적되는 곡선, PDF는 확률이 분포된 곡선이라고 볼 수 있다.
3. 균일분포 (Uniform Distribution)
균일분포는 일정 구간 [a, b] 내에서 확률이 모두 동일한 분포이다.
즉, X가 어디에 있든 확률이 똑같다.
확률밀도함수 (PDF)
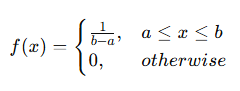
누적분포함수 (CDF)

그래프는 [a, b] 구간에서 일정한 높이의 직사각형 형태를 띤다.
균일분포의 평균과 분산

📌 균일분포의 핵심: 모든 구간이 동일 확률 → “무작위 추출(Random)”의 기초 개념.
4. 정규분포 (Normal Distribution)
정규분포는 통계에서 가장 중요한 연속형 확률분포다.
데이터의 자연스러운 변동을 설명할 때 거의 항상 등장한다.
X ~ N(μ, σ²)
- 평균 μ: 분포의 중심
- 분산 σ²: 분포의 퍼짐 정도
확률밀도함수
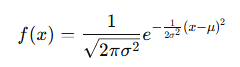
곡선은 평균 μ를 중심으로 좌우 대칭이며, σ가 커질수록 완만하고, 작을수록 뾰족하다.
정규분포의 특징
- 평균 = 중앙값 = 최빈값
- 분포 전체 면적 = 1
- 68–95–99.7 법칙 (표준편차 기준)
σ 범위 1 → 약 68%
σ 범위 2 → 약 95%
σ 범위 3 → 약 99.7%
5. 표준정규분포 (Standard Normal Distribution)
정규분포를 평균 0, 표준편차 1로 변환한 분포.
변환 식은 다음과 같다.
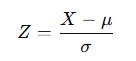
따라서
X ~ N(μ, σ²) → Z ~ N(0, 1)
Z값은 “평균에서 몇 표준편차 떨어져 있는가”를 의미하며,
확률은 표준정규분포표(Z-table)로 확인한다.
예시)
- P(Z ≤ 1.96) = 0.975
- P(Z ≤ -1.96) = 0.025
- P(–1.96 ≤ Z ≤ 1.96) = 0.95
6. 정규분포의 변환과 성질
| 상황 | 변환 결과 |
| X ~ N(μ, σ²), aX + b | N(aμ + b, a²σ²) |
| 표준화 Z = (X - μ)/σ | N(0, 1) |
| X, Y 독립일 때 aX + bY | N(aμ₁ + bμ₂, a²σ₁² + b²σ₂²) |
예시)
X ~ N(100, 10²) 일 때
P(100 ≤ X ≤ 110) = P(0 ≤ Z ≤ 1) = 0.3413
7. 이항분포의 정규 근사
n이 충분히 크고 p가 0에 가깝지 않을 때,
이항분포 B(n, p)는 정규분포 N(np, np(1-p))로 근사 가능하다.
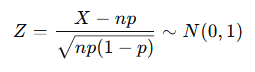
이 근사는 실제로 샘플이 많을수록 평균이 정규분포에 가까워지는 현상
즉, **중심극한정리(Central Limit Theorem)**의 기반이 된다.
* 이 글은 제로베이스 데이터사이언스 파트타임 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
💡 생각 정리
연속형 확률분포는 현실의 수많은 변동을 수학적으로 모델링하는 방법이다.
- PDF는 ‘확률의 밀도’,
- CDF는 ‘누적 확률’,
- 정규분포는 ‘자연스러운 데이터의 패턴’.
이 개념을 이해하면 데이터를 “확률 공간에서 해석”할 수 있다.
즉, 정규분포는 통계학의 언어이자,
모든 데이터 분석의 기본 배경이다.
🚀 적용점
- EDA 확장 분석 : 연속형 변수의 분포 시각화 (히스토그램, KDE plot)
- 확률계산 : 특정 구간 확률 계산 시 scipy.stats.norm.cdf() 사용
- 표준화(Z-score) : 이상치 탐지, 데이터 스케일링
- 데이터 샘플링 : np.random.normal(μ, σ, n) 으로 정규분포형 데이터 생성
import numpy as np
from scipy.stats import norm
import matplotlib.pyplot as plt
# 정규분포 PDF
x = np.linspace(-4, 4, 100)
y = norm.pdf(x, 0, 1)
plt.plot(x, y)
plt.title('Standard Normal Distribution')
plt.show()
'데이터' 카테고리의 다른 글
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-7 (0) | 2025.11.14 |
|---|---|
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-6 (0) | 2025.11.13 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-4 (0) | 2025.11.11 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-3 (0) | 2025.11.10 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-2 (0) | 2025.11.09 |