Chapter 01. 기초통계_기초과정
모집단 · 표본 · 표본분포 개념 요약
- 모집단(Population): 전체 대상의 집합
- 표본(Sample): 모집단에서 추출한 일부 데이터
- 표본추출(Sampling): 모집단에서 표본을 뽑는 과정
- 표본분포(Sampling distribution): 표본으로 계산된 통계량이 이루는 분포
- 중심극한정리(CLT): 표본의 크기가 충분히 크면 표본평균은 정규분포를 따른다
- 불균형 데이터(Imbalanced data): 클래스 비율 차이로 발생하는 문제
- Sampling 기법: Oversampling / Undersampling 등
1. 모집단(Population)과 표본(Sample)
모집단과 표본의 개념
- 모집단(Population)
우리가 알고 싶은 전체 데이터의 집합- 평균: μ
- 분산: σ²
- 표본(Sample)
모집단에서 일부만 추출한 데이터- 표본평균: 𝑋̄
- 표본분산: s²
표본을 통해 모집단의 특성을 추정하는 것이 통계의 핵심 작업이다.
표본추출(Sampling)의 종류
1) 복원추출 (Sampling with replacement)
- 하나 뽑고 → 다시 넣고 → 또 뽑는 방식
- 같은 데이터가 여러 번 선택될 가능성이 있음
2) 비복원추출 (Sampling without replacement)
- 뽑은 데이터는 제거됨
- 중복 없음
3) Random Sampling(단순 랜덤 표본추출)
- 모든 개체가 동일한 확률로 선택됨
- 편향을 최소화할 수 있는 가장 기본적이고 중요한 추출 방식
불균형 데이터(Imbalanced Data)
- 관심 있는 대상(예: 사기 거래, 불량품 등)의 비율이 매우 낮을 때 발생
- 모델이 대부분 다수 클래스만 맞추더라도 높은 정확도를 갖는 문제 발생
→ 실제 성능은 매우 나쁨
해결법
- Sampling 기법 사용
- Cost-sensitive Learning
(소수 클래스 오류 비용을 높게 부여하여 모델이 더 신경 쓰게 만듦)
Sampling 기법 상세
Oversampling (소수 클래스 늘리기)
- 적은 클래스 데이터를 복원추출을 통해 인위적으로 늘리는 방식
- 장점: 데이터 균형 개선
- 단점: 과적합 위험 증가
Undersampling (다수 클래스 줄이기)
- 많은 클래스에서 일부만 사용
- 장점: 간단하고 빠름
- 단점: 정보 손실, 편향 가능
2. 표본분포(Sampling Distribution)
통계량(Statistic)
표본에 기반해 계산되는 수치
- 대표: 표본평균 𝑋̄, 표본분산 s²
표본 분포란?
- 표본을 여러 번 뽑아 각각의 평균을 계산했을 때,
그 표본평균들의 분포가 바로 표본분포
표본 평균의 기대값과 분산
표본크기 n의 표본평균 𝑋̄에 대해,
표본평균의 기대값

→ 표본평균의 평균은 모집단 평균과 동일함
📌 표본평균의 분산

→ 표본 크기가 커질수록 분산이 작아짐 → 평균이 더 안정적
중심극한정리(Central Limit Theorem)
핵심 개념
모집단의 분포가 어떤 모양이든
표본 크기가 충분히 크면(n ≥ 30),
표본 평균 𝑋̄는 근사적으로 정규분포를 따른다.
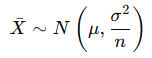
예시 문제 1
모집단:
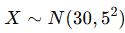
표본크기 n=30일 때,
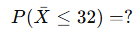
해설 결과:

예시 문제 2
모집단 평균 80, 표준편차 10
표본 100명을 뽑을 때, 표본평균이 80 이하일 확률?
결과:

대칭 정규분포의 특징 그대로 적용됨.
* 이 글은 제로베이스 데이터사이언스 파트타임 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
💡 생각 정리
모집단과 표본의 관계를 이해하는 것은 통계 전체를 이해하는 출발점이다.
실제 분석에서는 모집단의 모든 데이터를 확보하기 어렵기 때문에, 우리는 항상 표본을 통해 모집단을 추정하게 된다.
표본이 우연에 의해 흔들릴 수 있지만, 표본평균이 모집단 평균으로 수렴하고 분산이 줄어드는 성질 덕분에 통계적 추정이 가능해진다는 점이 핵심이다.
특히 중심극한정리는 어떤 분포라도 표본만 충분히 크다면 정규분포의 형태를 갖게 한다는 매우 강력한 원리로, 머신러닝과 데이터 분석에 적용되는 수많은 기법의 기반이 된다.
또한 불균형 데이터 문제처럼 실제 환경에서 자주 마주치는 데이터 편향 이슈의 존재를 고려해야 하고, 적절한 샘플링 전략을 통해 훈련 데이터의 품질을 높이는 것이 중요함을 다시 느끼게 된다.
🚀 적용점
- 분석용 데이터를 가져올 때 Random Sampling을 반드시 고려할 것
- 불균형 데이터의 비율을 항상 먼저 확인하고 Oversampling/Undersampling 여부 결정
- 모델링 시 표본평균·표준오차(σ/√n)를 계산해 통계적 신뢰성을 체크
- 표본 크기 n ≥ 30 이상 확보하면 중심극한정리 적용 가능
- A/B 테스트나 금융 모델링처럼 확률 기반 판단이 필요한 작업에 바로 활용 가능
- 표본분포 개념은 나중에 배우는 신뢰구간, 가설검정의 핵심이므로 지금 확실히 익혀둘 것
'데이터' 카테고리의 다른 글
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-9 (0) | 2025.11.16 |
|---|---|
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-8 (0) | 2025.11.15 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-6 (0) | 2025.11.13 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-5 (0) | 2025.11.12 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-4 (0) | 2025.11.11 |