반응형
Chapter 01. 기초통계_기초과정
연속형 확률분포 완전 정리 (pdf · cdf · 균일 · 정규 · 지수)
1. 주요 개념 요약
확률밀도함수(pdf)
- 연속형 확률변수 X의 “확률 분포 형태”를 나타내는 함수
- 모든 x에 대해 f(x) ≥ 0
- 전체 면적 = 1

- 구간 확률은 면적

- P(X = a) = 0 → 경계 포함 여부는 중요하지 않다.
누적분포함수(cdf)
- “특정 값 이하일 확률”
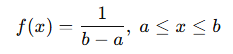
- pdf의 적분
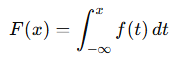
- 구간 확률
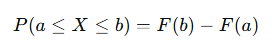
균일분포(Uniform)
X ~ U(a, b)

평균, 분산

정규분포(Normal)
X ~ N(μ, σ²)

특징
- 종 모양, 대칭
- 자연계 대부분의 값이 근사적으로 따름
- 평균 μ, 분산 σ²로 완전히 결정
표준정규변환
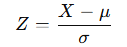
이항분포의 정규 근사
n이 충분히 크면
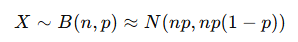
지수분포(Exponential)
X ~ Exp(λ)
어떤 사건이 “처음 발생할 때까지 걸리는 시간”

평균
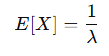
무기억성
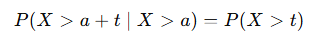
포아송–지수 관계
- 단위 시간 동안 발생하는 횟수 → 포아송(λt)
- 각 사건 사이의 대기시간 → 지수(λ)
두 분포는 같은 과정에서 서로 연결된다.
2. 예시 & 수식 정리
● 표준정규 분포 예시
- P[Z≤1.96]=0.975
- P[Z≤−1.96]=0.025
- P[0.5≤Z≤1.96]=0.975−0.6915=0.2835
● 정규분포 예시
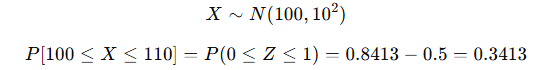
● 지수분포 예시
버스가 시간당 6대 도착 → λ = 1/10
- 10분 이상 대기할 확률
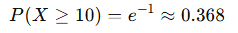
- 10~20분 대기할 확률
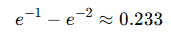
* 이 글은 제로베이스 데이터사이언스 파트타임 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
💡 생각 정리
이번 파트를 공부하면서 느낀 건, ‘연속형 확률분포’라는 큰 틀이 사실 서로 연결된 개념들의 자연스러운 흐름이라는 점이다.
- pdf는 형태
- cdf는 누적
- 정규는 자연 현상을 가장 잘 설명
- 지수는 사건과 사건 사이의 시간
- 포아송은 시간 동안의 횟수
이렇게 연속형·이산형 분포가 하나의 과정으로 묶여 있다는 게 인상적이었다.
특히 정규 근사와 포아송–지수 연결성은 앞으로의 모델링에도 계속 등장할 개념이라 확실히 잡아두는 게 중요하다고 느낌.
또 하나, 확률분포를 ‘암기’하려고 보면 어렵지만 “현실에서 어떤 상황을 설명하는지” 이미지화하면 훨씬 명확해진다.
정규는 키/점수, 균일은 랜덤 위치, 지수는 대기시간… 이렇게 현실 사례를 매칭하니 개념이 더 자연스럽게 머리에 들어왔다.
🚀 적용점
- ✔ 데이터의 분포 파악
EDA 과정에서 히스토그램을 보고 정규성 여부를 판단할 때 바로 이 개념들이 쓰인다. - ✔ 가설검정 / 신뢰구간 계산
표준정규 및 정규 근사는 모든 기초 통계 기법의 기반이 된다. - ✔ 머신러닝 모델링(특히 확률모형)
Gaussian Mixture Model, Naive Bayes 등은 정규분포를 기본 가정으로 삼는다. - ✔ 대기시간/고장시간 모델링
서버 요청 도착, API 호출 간격, 콜센터 업무량 분석 등에서 지수분포가 필수. - ✔ 시뮬레이션/랜덤 데이터 생성
균일분포는 random seed, 샘플링, 몬테카를로 시뮬레이션의 기본 분포. - ✔ 포아송–지수 관계 활용
“시간 동안 몇 번 발생?” vs “다음 발생까지 얼마나 남았나?”
두 개념을 상황에 맞게 선택할 수 있게 됐다.
반응형
'데이터' 카테고리의 다른 글
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-8 (0) | 2025.11.15 |
|---|---|
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-7 (0) | 2025.11.14 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-5 (0) | 2025.11.12 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-4 (0) | 2025.11.11 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-3 (0) | 2025.11.10 |