반응형
Chapter 01. 기초통계_기초과정
표본분포 정리: 카이제곱·t·F 분포까지 한 번에 이해하기
주요 개념
- 카이제곱 분포(χ²)
- 정규분포를 따르는 확률변수들 제곱합 → 카이제곱 분포
- 분산 추정, 적합도 검정 등에 활용
- t 분포
- 모표준편차를 모를 때 표본표준편차로 대체해 추론할 때 사용
- 자유도가 커질수록 정규분포에 수렴
- F 분포
- 두 개의 독립 표본 분산의 비율
- 분산분석(ANOVA)에 필수
1. 카이제곱 분포(Chi-square distribution)
정의
표준정규분포를 따르는 변수 Z1,Z2,...,Zn 이 있을 때,

여기서 vv는 자유도(degree of freedom).
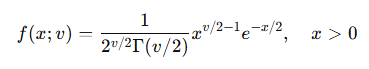
평균과 분산

감마분포와의 관계
카이제곱 분포는 감마분포의 특수한 경우이며

로 나타낼 수 있음.
활용
- 분산에 대한 추론
- 적합도 검정 (Goodness-of-fit Test)
- 범주형 데이터 분석
예시 문제
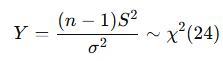
목표:

즉,
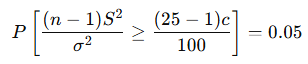
이를 이용해 카이제곱 분포표에서 임계값을 찾음.
자유도와 모양
- 자유도가 작으면 오른쪽 꼬리가 긴 비대칭 분포
- 자유도가 커지면 정규분포에 근사
2. t 분포(t-distribution)
배경
모표준편차 σ를 모르는 경우, 표본표준편차 s로 추정하여
확률변수 Z 대신 t 통계량을 정의.
정의

여기서
- Y∼χ2(v)
- v=n−1 (자유도)
특징
- 표본 크기가 작을 때 강력함
- 꼬리가 두꺼운 형태 → 극단값에 민감
- n 증가 → 정규분포에 수렴
예시
표본 25개, 모집단 N(100,10²)
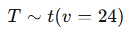
문제

→ t 분포표에서

값을 찾아 c=−1.711
3. F 분포(F-distribution)
정의
두 카이제곱 변수의 “평균화된 비율”

여기서

표본 분산의 비율
표본1, 표본2를 각각 추출하면

활용
- 두 집단의 분산 비교
- ANOVA (분산분석)
- 회귀 모델 유의성 검정 (F-test)
예시
모집단

표본 크기
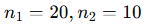
문제:
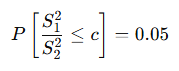
F 분포표에서

* 이 글은 제로베이스 데이터사이언스 파트타임 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
💡 생각 정리
표본분포는 단순히 ‘표본을 뽑았을 때 변하는 값의 분포’가 아니라, 모집단을 직접 확인하지 않고도 통계적 추론을 가능하게 해주는 핵심 도구라는 점이 다시 한 번 명확해졌다.
세 분포는 서로 독립적이 아니라 서로 긴밀하게 연결되어 있으며, 정규분포 → 카이제곱 → t → F 분포로 확장되는 구조를 이해하면 어떤 검정에서 어떤 분포를 쓰는지 자연스럽게 연결된다.
특히 자유도 개념은 처음엔 추상적이지만, 표본평균을 계산하면서 실제로 ‘제약 조건’이 생기는 과정에서 왜 감소하는지 알게 되니 훨씬 직관적으로 받아들여졌다.
🚀 적용점
- 데이터 분석에서
- 분산 비교 → F 분포
- 평균 차이 검정 (표본 작거나 σ 모름) → t 분포
- 범주형 적합도 검정 → 카이제곱
- 머신러닝에서
- ANOVA 기반 특징 선택 시 F 통계량 활용
- 모수 추정 정확도 판단 시 t 통계량 활용
- 분산 안정성 가정 검토 시 F-test 활용
- 프로젝트 실무에서
- A/B 테스트의 분산 동질성 여부 판단
- 품질 관리에서 변동성 분석
- 신용평가·제조 데이터처럼 분산 차이가 중요한 산업에 직접 적용 가능
반응형
'데이터' 카테고리의 다른 글
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-10 (0) | 2025.11.17 |
|---|---|
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-9 (0) | 2025.11.16 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-7 (0) | 2025.11.14 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-6 (0) | 2025.11.13 |
| 제로베이스 데이터사이언스 스쿨 - Part 04. 기초 통계-5 (0) | 2025.11.12 |